Position Sizing Strategy: A Conviction-Based Framework for Day Traders
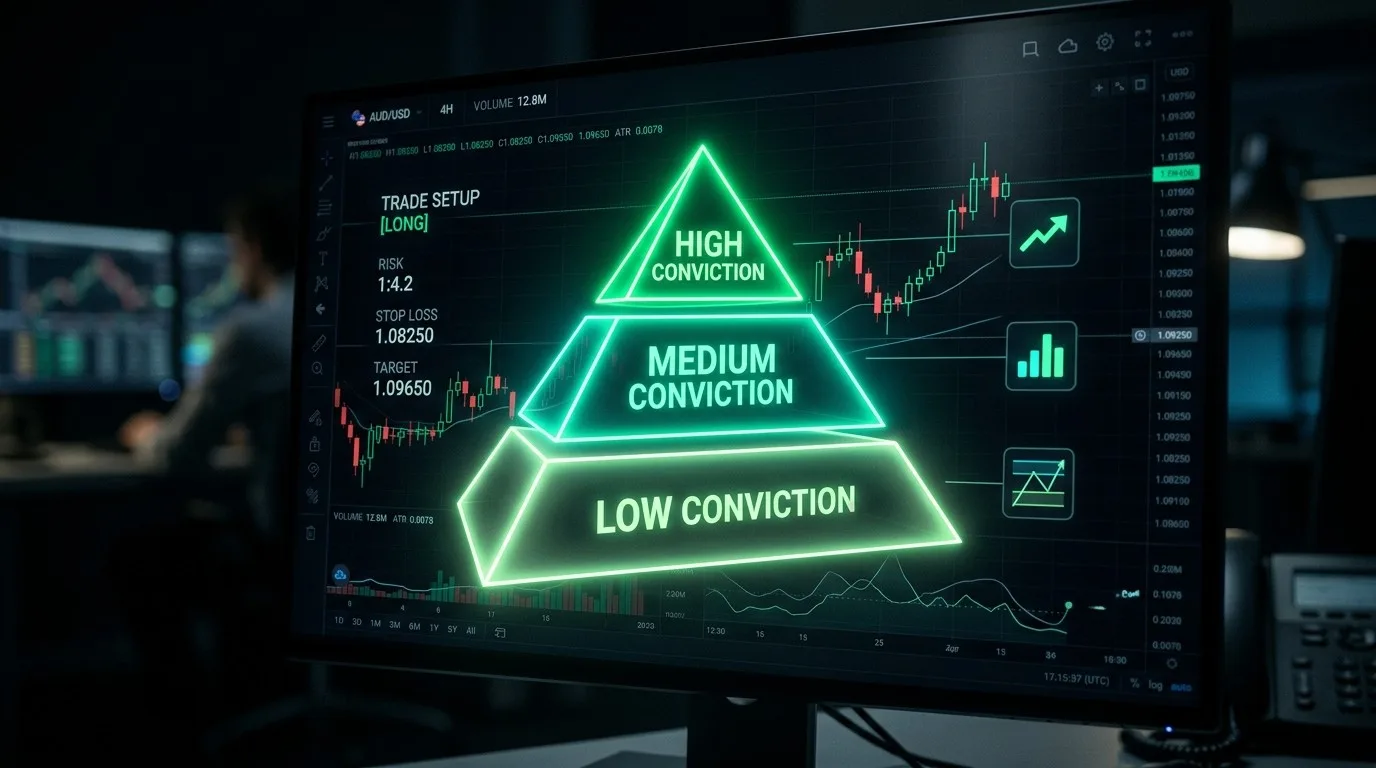
What is conviction-based position sizing?
Conviction-based position sizing matches trade size to the number of independent analytical dimensions that confirm it — not flat allocation across every setup. Count how many of five categories agree: trend, momentum, flow, structure, options positioning. Two categories = low conviction, half standard size. Three to four = standard. Five plus multi-timeframe alignment = 1.5–2× standard, capped at your maximum risk per trade. The framework captures edge that fixed sizing leaves on the table.
You've taken the same position size on every trade for months. Some of those trades had five independent reasons to work. Others had two at best. You gave them identical capital, identical risk, and identical opportunity to affect your account.
The five-signal setups earned what the two-signal setups deserved. The two-signal setups lost what the five-signal setups should have had. And your equity curve, after hundreds of trades, looks flatter than it should because conviction never entered the equation.
There's a different version of this problem. Instead of fixed sizing, you size on feeling. Big when you're confident, small when you're nervous. The confident trades often come after winning streaks, when overconfidence inflates your read. The small trades come after losses, when fear shrinks your exposure on exactly the setups that might recover the drawdown.
Both approaches leave edge on the table. One through rigidity, the other through emotion.
Why Fixed Position Sizing Costs More Than It Saves
Fixed sizing protects traders from emotional overexposure, but it treats every trade as if the evidence behind it were identical. The number of genuinely independent data dimensions confirming a setup varies from trade to trade, and matching size to that variation captures edge that flat allocation misses.
The logic behind fixed sizing is understandable. If every trade gets the same allocation, no single loss can do disproportionate damage. Risk management textbooks have taught this for decades, and for traders who struggle with discipline, it's a reasonable starting point. Ralph Vince demonstrated in The Mathematics of Money Management (1990) that position sizing is the single variable with the largest impact on terminal wealth across a series of trades, yet most traders treat it as a constant rather than a variable.
The problem is that "constant" sizing implicitly assumes all setups carry the same probability. They don't. A setup where trend direction, momentum, order flow, structural positioning, and options data all agree is not the same as one where only momentum and trend align. Both might be valid entries according to your rules. But the first has more independent evidence behind it, and the probability distribution for that trade is different from the second.
When you size them equally, you underweight the strong setup and overweight the weak one. Over hundreds of trades, that misallocation compounds. Not catastrophically, not in a single session, but steadily, like a drag coefficient that keeps your equity curve 15–20% flatter than it could be.
The prerequisite for variable sizing is a way to measure conviction objectively. If conviction is a feeling, variable sizing is just emotional sizing with better vocabulary. If conviction is a count of independent confirming signal categories, it becomes something you can build rules around.
How to Score Conviction with Independent Signal Categories
Conviction becomes measurable when you count how many genuinely independent analytical dimensions confirm a trade thesis simultaneously. Independent means the signals derive from different data sources and measure different market properties, so agreement between them is meaningful rather than redundant. Five categories provide a practical scoring framework: trend, momentum, flow, structure, and positioning.
These five aren't arbitrary. Each measures something the others can't see.
- Trend tracks directional bias across timeframes. Is price above or below key moving averages? What does Supertrend show? Are multiple timeframes aligned? Trend tells you which side of the market has structural wind at its back.
- Momentum measures the intensity of movement within the current trend. RSI, MACD, rate of change. These describe how strongly price is moving in its current direction. Momentum can be strong in a weak trend or weak in a strong one, which is precisely why it's independent from trend.
- Flow reveals who's actually buying and selling aggressively. Cumulative volume delta, on-balance volume, the accumulation/distribution line. Flow answers a question momentum can't: is the move backed by aggressive participation, or is price drifting on thin volume? A price rally where flow data shows passive buying is a fundamentally different setup than one with aggressive institutional accumulation.
- Structure refers to the price architecture around the current level. Are there untested order blocks? Unmitigated fair value gaps? Has a break of structure or change of character occurred? Structure tells you whether the current price sits at a mechanically significant zone or in open space.
- Positioning covers options-derived intelligence where available. Open interest concentration, put/call ratio, gamma exposure regime. Positioning reveals where institutional hedging activity creates mechanical support or resistance, independent of anything the chart shows.
The independence is what matters. RSI agreeing with MACD is not two signals. It's one signal measured twice, because both derive from the same price momentum data. RSI agreeing with cumulative volume delta is two signals, because they measure different properties of the market. The distinction between false confluence (correlated indicators agreeing) and real confluence (independent dimensions agreeing) is what separates a count you can size on from a count that misleads.
Three Tiers of Conviction
Once you can count independent confirming categories, the sizing framework becomes straightforward.
- Low conviction (2 independent categories confirming): This is a valid setup by your rules, but the evidence is thin. Only two dimensions agree. Size at your minimum allocation. For a trader risking 1% of capital per trade as a baseline, low conviction might mean 0.5%.
- Medium conviction (3–4 independent categories confirming): Three or four dimensions agree. The weight of evidence is materially stronger. Size at your standard allocation. This is the 1% baseline for most traders.
- High conviction (5 independent categories confirming, with multi-timeframe alignment): All five dimensions agree, and the signal persists across at least two timeframes. This is statistically rare, occurring perhaps 10–15% of the time depending on your instruments and methodology. Size at 1.5x to 2x your standard allocation, within your maximum risk cap.
The specific multipliers aren't sacred. A trader who risks 0.75% as a baseline might scale to 1.25% on high conviction. The principle is what matters: size varies with evidence, and the variation follows a predefined rule rather than a real-time judgment call.
Why Traders Size Wrong Even When They Know Better
The conviction-to-size framework is simple to understand and difficult to execute, because human risk psychology works against variable sizing in both directions. Traders consistently undersize their strongest setups and oversize their weakest ones, not from ignorance but from deeply wired cognitive patterns that distort how evidence feels in the moment.
Kahneman and Tversky's prospect theory, published in Econometrica in 1979, demonstrated that losses feel roughly twice as painful as equivalent gains feel pleasurable. This asymmetry has a direct consequence for position sizing: when a high-conviction setup appears and the framework says to size up, the trader's loss aversion calculates the potential loss at the larger size and recoils. The analysis says 1.5x. The gut says "but if I'm wrong, that loss is 50% bigger." The gut usually wins.
The result is that high-conviction setups get sized at standard or even below standard. The trader takes the trade, it works, and the profit is 60% of what it should have been. Multiply that across dozens of high-conviction trades over a quarter, and the drag is substantial.
The reverse problem is equally damaging. After a winning streak, confidence inflates. A setup with two confirming categories feels like it has four because the trader's recent success biases their read. They size up on thin evidence. The SEBI "Analysis of Profit and Loss of Individual Traders dealing in Equity F&O Segment" (January 2023) found that 89% of individual F&O traders in India lost money over a three-year period, and one contributing factor was outsized losses on low-quality trades that erased gains from better ones.
There's a third pattern worth naming. Some traders acknowledge the framework intellectually but override it under pressure. They see five independent categories confirming, recognize the high-conviction tier, and then reduce size anyway because "the market feels off" or "it's Friday afternoon" or "I'm already up today and don't want to give it back." These overrides aren't always wrong. Sometimes the market does feel off for good reason. But when the override becomes habitual, it collapses variable sizing back into emotional sizing.
The fix isn't willpower. The fix is commitment: define the tiers before the session starts, write the rules on paper, and follow them mechanically for a minimum of 30 trades before evaluating. Thirty trades gives enough data to see whether variable sizing is capturing edge. Fewer than that, and you're measuring noise.
One useful guardrail: when signals conflict across categories, that's not a lower-conviction version of the same trade. It's a different condition entirely. A setup where trend and flow agree but structure and positioning disagree isn't a medium-conviction long. It's a conflicted read that might warrant standing aside altogether. Conviction scoring works for setups where the confirming categories point the same direction. When categories actively contradict each other, the sizing framework isn't the right tool. The signal hierarchy framework is.
The Risk Cap: Why Maximum Exposure Doesn't Move
Variable position sizing adjusts how much capital you deploy per trade, but it never adjusts the maximum you can lose on any single position. The risk cap stays fixed regardless of conviction, because even the highest-conviction setup can fail, and no amount of confirming evidence changes the fundamental truth that any individual trade can lose.
This is the constraint that makes variable sizing safe rather than reckless. Without it, a trader who scores five independent categories might convince themselves to risk 3% or 4% on a single trade. And they might be right seven times out of eight. But the eighth time, when the trade fails despite every dimension confirming, the outsized loss damages the account and, more importantly, damages the trader's confidence in the framework itself.
J.L. Kelly Jr.'s 1956 paper "A New Interpretation of Information Rate" in the Bell System Technical Journal introduced what traders now call the Kelly Criterion, which calculates optimal bet sizing given a known edge. The formula demonstrates that betting more than the Kelly-optimal fraction decreases terminal wealth even when the edge is real. The practical takeaway: sizing up beyond a certain threshold doesn't improve returns. It increases the probability of ruin.
For most retail day traders, a maximum risk cap of 1.5–2% of account equity per trade provides a reasonable ceiling. High-conviction setups size up to that ceiling. Low-conviction setups stay well below it. But nothing goes above it.
Practical Sizing Mechanics
The translation from conviction tier to actual position size requires two numbers: your risk cap and your stop distance.
- Step 1: Determine stop distance based on the trade's technical structure. If you're entering a NIFTY long at 23,400 with an invalidation level at 23,340, your stop distance is 60 points.
- Step 2: Determine your conviction tier based on independent category count. Say trend, momentum, and flow confirm the long, but structure is neutral and options positioning isn't available for this instrument. That's three confirming categories: medium conviction, standard size.
- Step 3: Calculate position size. If your account is ₹10,00,000 and your standard risk is 1%, you're risking ₹10,000. At 60 points stop distance, that's approximately 166 shares (or the lot-size equivalent in F&O).
- Step 4: If conviction were high (five categories plus multi-timeframe alignment), the risk allowance increases to 1.5%, or ₹15,000. Same stop distance, larger position: approximately 250 shares.
The stop doesn't change between tiers. The risk allocation does. This is a critical distinction. Some traders try to adjust conviction by tightening stops on lower-conviction trades, which reduces position size but also increases the probability of being stopped out on noise. The stop goes where the trade thesis invalidates. Conviction adjusts the capital allocated to that stop distance.
For US instruments, the same logic applies with different numbers. A SPY entry at $528 with a $525 invalidation gives a $3 stop. At 1% risk on a $50,000 account, that's 166 shares. At 1.5% risk, 250 shares. The framework is instrument-agnostic because it operates on percentages and structural levels, not fixed point values.
Putting It Together Before Every Trade
The practical application of conviction-based sizing is a 30-second checklist that runs between identifying the setup and clicking the order button. Count the independent categories confirming. Map the count to your predefined tier. Calculate size from the tier's risk percentage and the trade's stop distance. Execute.
That checklist replaces the internal negotiation most traders conduct with themselves before every entry. "Should I go bigger on this one? It looks good." "Maybe I should go smaller, I've been wrong lately." Those negotiations are emotional sizing dressed up as analysis. The checklist short-circuits them because the answer was determined before the market opened.
The second opinion workflow fits naturally here. Before committing to a position, checking whether the categories you've counted genuinely confirm the thesis or whether you've double-counted correlated indicators is the difference between accurate conviction scoring and inflated confidence. Draconic, an AI trading intelligence platform, synthesizes across all five signal categories simultaneously, making the conviction count concrete rather than estimated. A query like "I see a demand zone on NIFTY 5-min at 23,400 with bullish trend and positive CVD. What am I missing?" returns whether structure, positioning, and higher-timeframe context agree or disagree.
In this example, five categories confirm the NIFTY long at 23,400. Trend is bullish across multiple indicators. Momentum is moderate but positive. Flow shows aggressive buying. Structure has an untested order block just below entry. And the 15-minute timeframe aligns with the 5-minute read. That's a high-conviction tier: 1.5x standard size, with the stop at 23,340 where the order block invalidates.
Without the synthesis, a trader might have seen the trend and momentum, guessed at flow, and ignored structure and positioning entirely. They'd have scored it as medium conviction and sized accordingly. The difference isn't just capital allocation. It's whether the sizing decision tracked the actual evidence or a partial estimate of it.
The Sizing Decision That Compounds
Position sizing based on measurable conviction isn't a technique that transforms your next trade. It's a structural advantage that compounds across hundreds of trades because it systematically allocates more capital to higher-probability setups and less to speculative ones. Over a quarter of active trading, even a modest improvement in capital allocation can materially change the equity curve.
The framework works because it replaces two unreliable inputs with one reliable one. It replaces gut feel (unreliable because emotions distort perception) and fixed sizing (unreliable because it ignores variation in setup quality) with a category count (reliable because it's predefined, binary, and verifiable after the fact). You either had five independent categories confirming or you didn't. There's no ambiguity, no rationalization, no post-hoc editing of the story.
Start with your existing risk parameters. Define the three tiers. Write them down. Run the framework mechanically for 30 trades. Then evaluate whether the high-conviction trades outperformed the low-conviction ones on a risk-adjusted basis. If they did, the framework is capturing a real edge in your trading. If they didn't, the category definitions need refinement, not the principle.
The trader who sizes every trade the same treats all setups as equal. The trader who sizes on feeling treats emotion as evidence. The trader who sizes on counted, independent confirmation treats measurable evidence as evidence. That third approach is the only one that scales.
More like this
May 12, 2026behind-the-price
Sector Rotation — The Macro Signal Most Traders Ignore
The Draconic Team • 3 min
May 11, 2026behind-the-price
How Market Makers Create Invisible Floors and Ceilings
The Draconic Team • 11 min
May 8, 2026behind-the-price
The Magnetic Levels — Why Price Gets Drawn to Certain Numbers Near Expiry
The Draconic Team • 8 min
May 7, 2026behind-the-price
When Three Flow Signals Agree Against Price
The Draconic Team • 4 min